
Recently I asked Google how many R's are in "Google." The AI Overview answered: "There is exactly 1 'r' in the word 'Google' (G‑o‑o‑g‑l‑e)." Of course, there are no R's in Google.
It's funny because nothing was at stake. No customer record leaked, no workflow broke, no payment went out the door. Still, I wouldn't laugh it off too quickly.
Here is a system that will read a fifty‑page contract and hand back a clean summary in seconds, yet it just miscounted the letters in a six‑letter word (ironically, when writing this, Opus 4.8 kept writing a five letter word!). The task wasn't hard. These models are simply uneven in ways that have nothing to do with how hard we'd expect something to be. Brilliant and brittle, often in the same minute.
And nothing about it looked like a mistake. The answer came back direct, polished, finished. Exactly like a right one.
That unevenness is the whole point. Now take the same kind of model off a search box and put it inside a company, which is exactly where these things are heading. It reads customer records and internal documents, queries the data warehouse, calls tools, updates systems, hands work to other agents, all on live business data, at machine speed.

Two ways it goes wrong
Right format. Wrong answer.
Certain, polished, and wrong, just like the R. It invents a figure, misreads a clause, signs off a compliance step that never passed. Or you tell it to leave the data alone and it reaches for it anyway.
Right work. Bad inputs.
A document shared too widely. A permission nobody revoked. A credential it should never have held. The model does everything right and still hands back something dangerous, because the inputs were rotten.
None of this is exotic. It's ordinary enterprise life. The data shifts, permissions drift, prompts get rewritten, models get swapped under you, and the model folds all of it into one fluent, confident answer. By the time the run finishes, the seams are gone. So you put an LLM judge on the end, or have someone skim the summary, and neither catches a thing, because a bad run and a clean run read exactly the same.
Brilliant and brittle, often in the same minute.
You can't test your way out


The usual instinct is to test for it, to catch it in evals before anything ships. But evals only cover what you already thought to check. You can test the cases you thought of; you can't test the ones you didn't, and that set is unbounded: every model and prompt change, times every user, document, permission, and tool. No developer imagines every case, and neither does the user, the prompt, or the test suite.
That is the real argument for supervision.
The chain is where the risk lives
Each of the usual controls sees a sliver. Identity confirms the access was technically allowed. DLP (data loss prevention) catches some sensitive data. A log shows a file was touched. Evals flag the failures you already knew to look for. All useful, and all partial.
What none of them shows is the whole chain: the request, the agent's decisions, the data it touched, the permissions it leaned on, the tools it called, the output it produced. Any one step can look perfectly defensible on its own. The risk only shows up once you can see them in order.
This is why agents need supervision in real time: watching what they actually do in production, in context, while they do it.
- Was this agent supposed to use that tool?
- Was this user supposed to access that data?
- Did the agent follow the prompt?
- Was this output safe to send?
Policy that's enforced, not filed

This is where policy earns its keep. Not as paperwork, but as your organization's working definition of acceptable behavior. Stay out of records beyond the user's business context. Keep internal data away from unsanctioned tools. Wait for a human before proceeding when the workflow calls for one.
Policy isn't only about what an agent may touch. It's also about how it does the work. Call it an LLM best‑practices rule: don't do in your head what a sanctioned tool should do for you. No mental arithmetic, no counting by eye, no guessing a number the system could look up. That is the R exactly. The model counted in its head, trusted itself, and a tool built to count would have caught it.
But you can only enforce that if you can see how the answer was reached, and the answer itself never tells you. "Exactly 1 'r' in Google" shows no working. A number computed with a tool and a number pulled from thin air look identical on the page. Supervision watches the run itself, which tools were called and, just as telling, which weren't, so the method is visible and a shaky shortcut gets caught before it reaches the reader.
What this looks like at Classie
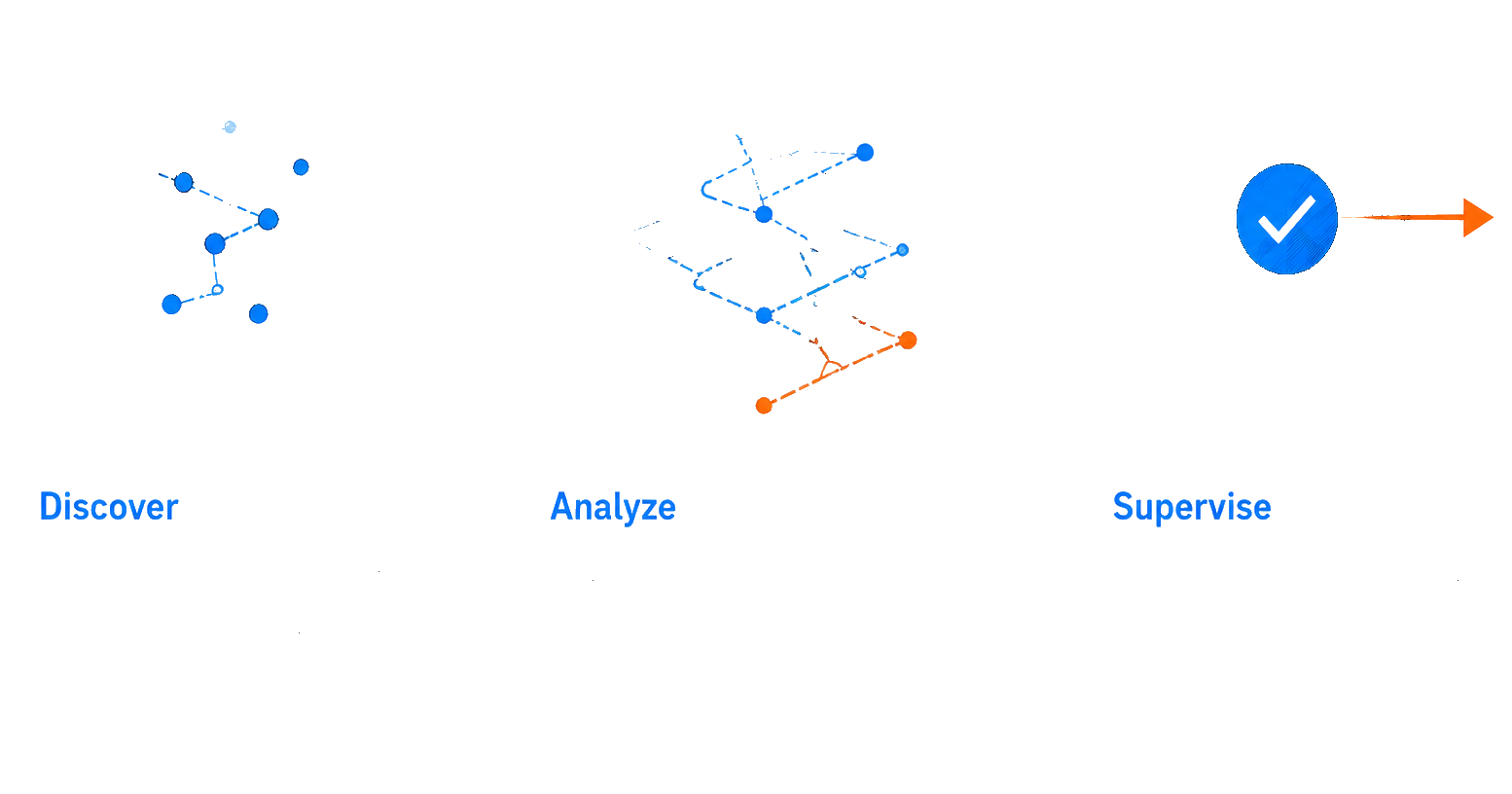
At Classie, this is the layer we built. Classie OBS‑SEC helps enterprises Discover, Analyze, and Supervise AI agents across the organization.

The point of the imaginary R was never that we need a spelling policy. It's that these systems are uneven, capable one moment and fragile the next, and we're wiring them into work that matters. The same flaw that invents a consonant can just as easily mishandle a customer record, and no one can promise it won't.
And in both cases, the wrong answer looks exactly like the right one.
The question worth asking is simpler. Can you see what your agents are doing, follow the chain behind any given answer, and step in before a weak moment turns into an incident?
That chain is the whole answer. The R looked right and no eval would have flagged it, but the run told the truth: a number counted in the model's head when a tool to count it sat right there, unused. The output hid the mistake. The chain exposed it. That is the difference between hoping a model behaves and knowing what it did, and it is the difference between finding out now and finding out from a customer later.

